Mua Information Retrieval & Apache Solr
Information Retrieval & NLP
Solr
What is?
Features
Solr Architecture
Apache Lucene Overview
How Solr works?
Working with Solr
Concepts
Installing/Running Solr
Schema design
Solr Configuration
Indexing data
Querying
REST API
Http Client
Update handler
Searching API
SolrJ (Java API)
Setting class path
For maven
HttpSolrClient
EmbeddedSolrServer
Adding data to Solr
Adding unstructured data to Solr
Deleting
Searching
Data Import Handler
Customizing
Ranking
Data import handler
Personalization
Evaluation
Bring Solr To UI Application: DBLP Search
Overview
Solution
Sequence Diagram
Class Diagram
Implementation
UI
Conclusion
References
Information Retrieval & NLP
Defining by Stanford, Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers). For example, the information can be extracted from collection of documents, or even from images. There are many techniques can be used in IR, for instance:
- Vector space model
- Boolean model
- Or more complicatedly probability model etc.
By means of IR, and often use natural language processing (NLP) techniques, information can be extracted from text from various sources. Some NLP techniques can be listed to use in IR techniques like:
- N-Gram (for language recognition)
- Stemming algorithm, for example, these words can be understand as one case: open, opened, opening etc.
- Named entity recognition, eg, HANOI is a LOCATION, Harvey_Nash is a ORGANIZATION etc.
- Part of speech tagging, eg, HANOI is a noun, LOVE is a verb etc.
- And so on.
Using NLP techniques can reduce the huge amount of data to be processed. In IR, they immediately use NLP techniques in some stages, like indexing, searching.
How IR works?
The searches can be described in several steps: (1) accepting user query, (2) doing some pre-processing tasks from user query, like recognizing language, stemming, recognizing entity etc. (3) querying the indexed (that already pre-processed), (4) ranking the results, (5) returning the ranked results to users.
As shown, the significant jobs in the searches are: indexing, searching, and ranking. Luckily, the Solr can be used to solve the most important things. The next section will show up how what is Solr, how it works, and then how to implement (integrate with other frameworks/systems).
Solr
What is?
You may asked as usual, generally questioned, what is Solr? As mentioned in Information Retrieval section, the search process contains several steps, it accepts user queries and produces the results for those queries from the databases. The roles of the search engine are to return results as fast as possible, and the most accuracy/approximately/nearly the results that user expected. They should also accepts simple query in almost situations. In case of text search, to dramatically increase time to return results, they often think of full-text search. There are already full-text search, a built-in feature on some enterprise databases. However, the critical issue is that this is not enough in most case (i.e. Slow, not flexible etc.). The solution for the case is using some models like vector space model, or probability model, boolean model. Developing a system based on these models from scratch contains much ricks, and time consuming. Luckily, Solr can solve problem.
Solr (or Apache Solr) is an open source, based on Apache Lucene, which is used for indexing, searching the information from the specified data (or collection of documents) given. Solr provides IR capabilities. Solr is written in Java, hence it can basically run on almost OS.
Features
The features of Solr can be grouped by following factors:
- Communication & API
> Communication through HTTP
> Standard based open interfaces: XML, JSON
> Client APIs are written in many languages: java, scala, .net, python, php.
- Indexing
> Accept input: JDBC, CSV, XML, flat files
> Near real-time indexing
> Data is defined by schema, fields.
> Dynamic fields supported
> Schemaless supported
> Tika integration (supporting parsing pdf etc.)
- Searching
> Lucene query parsing
> Join, Filter supported
> Facet supported
- Distributing
> Can be deploying onto J2EE container, or self-container (standalone server)
> Can be Highly Scalable and Fault Tolerant with zookeper container
- Customizing: endpoint API, search workflow, update workflow.
More at:
Solr Architecture

Where:
- RequestHandlers – handle a request at a URL like /select
- SearchComponents – part of a SearchHandler, a componentized request handler
- Includes, Query, Facet, Highlight, Debug, Stats
- Distributed Search capable
- UpdateHandlers – handle an indexing request
- Query Parser plugins
- Mix and match query types in a single request
- Function plugins for Function Query
- Text Analysis plugins: Analyzers, Tokenizers, TokenFilters
- ResponseWriters serialize & stream response to client
- Data Import Handler: a plugin for importing data from RDBMS/RSS
- Apache Tika: another open source from Apache, which plugged in to extract content from unstructured data like pdf, word ...
Apache Lucene Overview
How Solr works?
In the text search, the user input normally is a text (word, phrase). Firstly, Solr will index all documents, and for each users’ query, Solr looks inside the indexes and return the fit results, that contain the user query. However, Solr offers more than that, it returns the results with more relevant to the user query by ranking the results by some algorithms. This section describes how Solr indexes, searches, and ranks? The detail of each section could be found in next section [Working with Solr].
- Indexing: Solr is built under Lucene, which is an inverted full-text indexes. That means, all the words of all documents will be indexed. Since the indexes is an exact string-match, unordered, it becomes extremely fast when searching. The index reader module of Solr will care the reading mechanism the indexes that we don’t need to know (in fact, reading a flat file is very very fast).
- Searching & Ranking the results: as said, each word is stored in the inverted indexes, the search activity just looks for the documents contain the query that the indexes referenced to. Currently, the results ranking mechanism is based on vector space model (term frequency, document frequency), one technique of IR. Hence, for some specified tasks of ranking the results, for instance, it does not depends on frequencies of words/documents, we have to override the ranking model. Some techniques can be used are described in section [Ranking the results].
Working with Solr
Following practices are for Solr v5.1, and can be found at: http://lucene.apache.org/solr/
Concepts
When working with Solr, you may concern their definitions:
Keyword
|
Definition
|
Core/Collection
|
The core or collection is nothing but a name refer to a group of index that your data stored in. its equivalent is schema in RDBM definitions.
|
Solr instance
|
An instance of built-in server (based on jetty)
|
Indexing/updating
|
The definition for indexing operation.
|
Flatten data
|
In Solr, the indexing data does not allow nested or relationship data. If you want to keep relationship, you have to manage it by yourself.
|
Lucene query, DisMax, eDisMax
|
Type of query parser have been used in Solr.
|
Installing/Running Solr
After downloading and extracting to a folder, we can start an instance of Solr by the command:
- Starting:
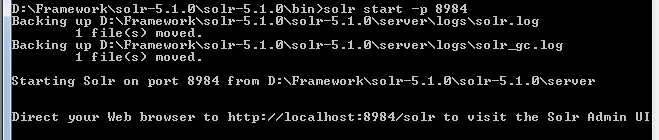
Navigating browser to: http://localhost:8984/solr to manage the instance. Note, the Solr server can be started in foreground by adding option -f.
To create a core, typing:

The core is created:

- Stopping an instance of Solr:

- Update data (indexing operation):
The data can be updated via REST API, a Client-API can be used to make it easier in communicating with the REST. However, this will be considered later in this document. To insert/update data, we POST an HTTP message with body is an xml/or json to REST API [http://localhost:PORT/solr/[core_name]/update], in my case, I posted following JSON data to API [http://localhost:PORT/solr/demo0/update]
[{"id" : "book1",
"myname" : "The Lord of dark",
"myaddress" : "The way you have to go over"
}]
For testing purpose, I used SOAP UI. In the figure below, I created a rest-resource to insert a data into [demo0].

Or when I get the data:
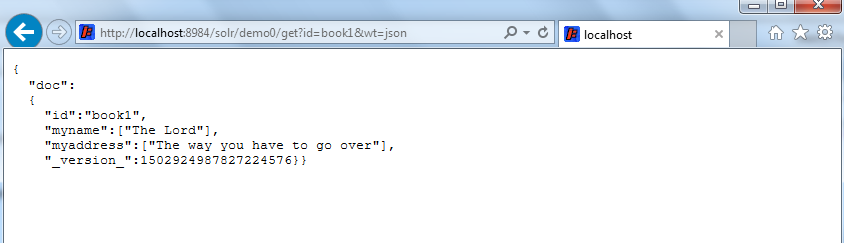
To get the result(s) in other formats, we specific option “wt=xml or csv”. The “get” command is one kind of request handler as considered in Solr Architecture. We also have other request handler like select etc.
Sample data: The Solr copy version contains sample data/examples which can be found at $SOLR\examples\. To use sample data, we can use a post tool comes with Solr to update several data. The example data can be found here: $SOLR\examples\exampledocs\. The command in Window look like:

Schema design
Unlike Solr 4.x, Solr 5.1 uses a managed schema by default. It guesses the type of data when we update the data. As an example from previous section, I added a book with two fields and unknown field types. This is schemaless mode by default. We cannot change the type of field after data are set. Therefore, we have to set fields’ type before we update data. The managed schema is located in: $SOLR_HOME\server\solr\$CORE_NAME\managed-schema. The generated fields are based on following rules:
Field Suffix
|
Multivalued Suffix
|
Type
|
Description
|
_t
|
_txt
|
text_general
|
Indexed for full-text search so individual words or phrases may be matched.
|
_s
|
_ss
|
string
|
A string value is indexed as a single unit. This is good for sorting, faceting, and analytics. It’s not good for full-text search.
|
_i
|
_is
|
int
|
a 32 bit signed integer
|
_l
|
_ls
|
long
|
a 64 bit signed long
|
_f
|
_fs
|
float
|
IEEE 32 bit floating point number (single precision)
|
_d
|
_ds
|
double
|
IEEE 64 bit floating point number (double precision)
|
_b
|
_bs
|
boolean
|
true or false
|
_dt
|
_dts
|
date
|
A date in Solr’s date format
|
_p
|
location
|
A lattitude and longitude pair for geo-spatial search
|
For instance, when we add new data with field name ends with “_t”, that field will be general text. For each dynamic field that this is corresponding to a actual field type, like this line in managed-schema. . i.e. field type ending with _txt_en is a text_end type.
There will be a way to decide when our indexes/queries are preprocessed. It depends on field type. For each field type, analyzer index/query is provided. Particularly, it is included in file managed-schema (or schema.xml). These analyzers are factory classes which are used to create instance of filters. There are many filters like Stemming, Stopword …. For example, with field type “text_en” will includes some filter for Porter stemming, or stopword removing for English. We can also view field list/and its analyzers by admin tool (by going to admin tool, and see the schema design from selected core).
The way to manage scheman yourself is via REST. The full guide is here: https://cwiki.apache.org/confluence/display/solr/Schema+API.
Almost REST API in Solr Webservices allows POST with body is xml,json. For example, the figure below shows how I added a field with name “sell-by” to the managed-schema:
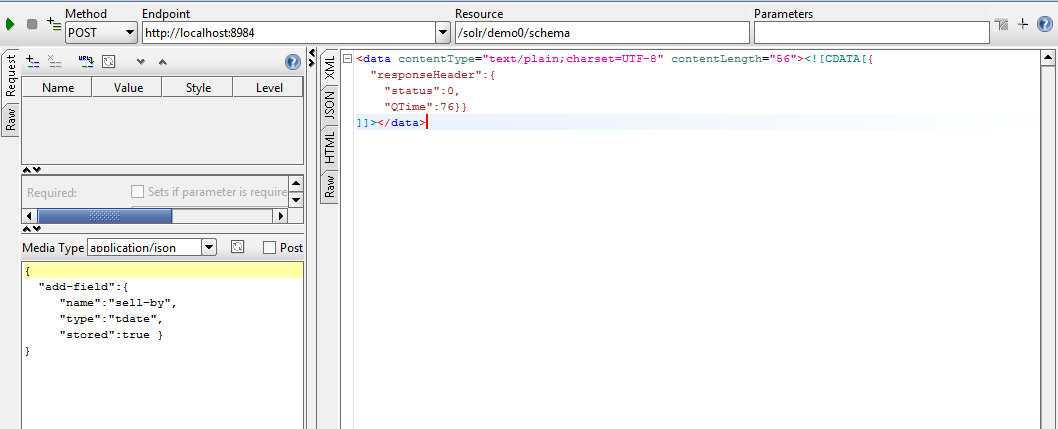
Solr Configuration
The solr configuration in version 5.x are available in two file:
Solr-config.xml and managed-schema
With Solr-config.xml we can modify to add more feature like Data import handler, add class path....
Indexing data
Solr accepts some kinds of data: csv, json, xml, pdf, office file, and we can even index it using JDBC, or customizing the DataImportHandler. Two ways to index the data:
- Update files via HTTP request.
- Writing custom application based on Client API coming with Solr.
- Using Data import handler
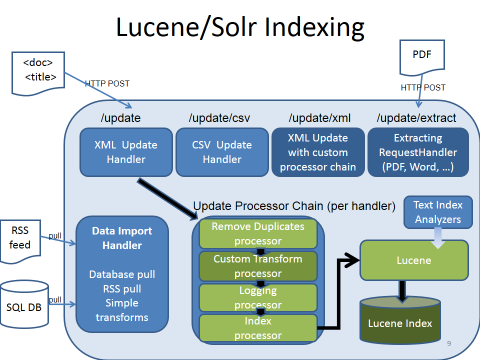
The best way for the first method is that, we should use a simple system that can generated data from [input-sources] to the accepted file (csv, json, xml...), and automatically send HTTP request. The second method is more simplify to whom understand at least one languages that Client-API support.
For special data types, like pdf, word, excel, we can use Tika, or Solr Cell to parse the data.
A dblp-search application (bring-solr-to-ui-application) has been written that enclosed with this document, contains the the java codes that communicates with Solr server instance via Solr Client-API. BS2U application is just a play! application that contains scheduler that crawl the data from internet, create xml files, and insert into solr collections.
Querying
Querying or searching, in general, it simply define that system accepts user query and returns the results that nearest to what the user expected. The user query should be as much simplicity as possible, in almost case. Luckily, Solr can do full-text searches. As mentioned, Solr searches in inverted indexes that contains all words of all documents, then the querying in Solr is extremely fast.
To process a search query, a request handler calls a query parser, which interprets the terms and parameters query parser of a query. Different query parsers support different syntax. The default query parser is the query parse DisMax. Solr also includes an earlier "standard" (Lucene) query parser, and an (eDisMax) query parser Extended DisMax. The query parser's syntax allows for greater precision in searches, but the DisMax query parser is standard much more tolerant of errors. The DisMax query parser is designed to provide an experience similar to that of popular search engines such as Google, which rarely display syntax errors to users. The Extended DisMax query parser is an improved version of DisMax that handles the full Lucene query syntax while still tolerating syntax errors. It also includes several additional features.
The querying feature of Solr supports following:
- Different querying parser
- Pagination
- More like this
- Grouping
- Faceting
- And so on
Note: the querying can be referred in the “apache-solr-referred-guide-5.1.pdf”.
REST API
Rest API is available via few request handlers:
- Update handler.
- Schema API: this usually handled automatically by Solr. The developer need not caring this feature. Guide at: https://cwiki.apache.org/confluence/display/solr/Schema+API.
- Searching API: available via http://localhost:8984/solr/[core_name]/select
Http Client
There are many ways to communicate with REST, in this case, I used apache http client to post data.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Map;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.HttpClientBuilder;
import connector.T;
public class HttpPostUtil {
public static String postString(String uri, Map headers, String contentType, String body) throws ClientProtocolException, IOException{
HttpClient httpClient = HttpClientBuilder.create().build();
T.info("Posting to %s: %s", uri,body);
HttpPost p = new HttpPost(uri);
StringEntity entity = new StringEntity(body);
entity.setContentType(contentType == null?"text/plain":contentType);
p.setEntity(entity);
HttpResponse response = httpClient.execute(p);
BufferedReader br = new BufferedReader(
new InputStreamReader((response.getEntity().getContent())));
StringBuilder sb = new StringBuilder();
String output;
while ((output = br.readLine()) != null) {
sb.append(output);
}
return sb.toString();
}
}
Update handler
- Update handler: allows update csv, xml, json content. URL: http://localhost:8984/solr/[core_name]/update
Before post data to this URL, [content-type] should be initialized in http message, the body content may be xml, json, or csv.
Content-type: supporting [application/xml, text/csv, text/json, application/csv, application/javabin, text/xml, application/json]
Body:
XML:
<add commitWithin="10">
<doc>
<field name="id">xml01</field>
<field name="content_type">text/xml</field>
<field name="name_s">the world of dark - 6</field>
<field name="title_t">No sunshine today</field>
<field name="address_s">In the air</field>
</doc>
....
</add>
JSON:
[
{
"id":"json01",
"name_s":"Nightwish",
"title_t":"Sleeping sun",
"address_s":"US"
},
{
"id":"json02",
"name_s":"Dreamed a dream",
"title_t":"It is just subjective",
"address_s":"In the darken sky"
}
]
CSV:
id,name_s,title_t,address_s
01,Noname,Superman - 0,Not given
02,Micheal,Batman - 0,Not given
03,Julia,Batgirl - 0,Not given
Indexing with Update handler
XML file: commitWithin (in ms) is attribute to commit after time.
<add commitWithin="10">
<doc>
<field name="id">xml01</field>
<field name="content_type">text/xml</field>
<field name="name_s">the world of dark - 6</field>
<field name="title_t">No sunshine today</field>
<field name="address_s">In the air</field>
</doc>
<doc>
<field name="id">xml02</field>
<field name="content_type">text/xml</field>
<field name="name_s">Possible or Impossible - 6</field>
<field name="title_t">It is just subjective</field>
<field name="address_s">In the darken sky</field>
</doc>
</add>
JSon file:
[
{
"id":"json01",
"name_s":"Nightwish",
"title_t":"Sleeping sun",
"address_s":"US"
},
{
"id":"json02",
"name_s":"Dreamed a dream",
"title_t":"It is just subjective",
"address_s":"In the darken sky"
}
]
CSV file:
id,name_s,title_t,address_s
01,Noname,Superman - 0,Not given
02,Micheal,Batman - 0,Not given
03,Julia,Batgirl - 0,Not given
Java snippet codes:
//supporting contentTypes: [application/xml, text/csv, text/json, application/csv, application/javabin, text/xml, application/json]
public static void main(String[] args) throws Exception{
//post(fromFile("./data/data.xml"),"text/xml");
//post(fromFile("./data/data.json"),"text/json");
post(fromFile("./data/data.csv"),"text/csv");
}
public static String fromFile(String f) throws IOException{
return FileUtils.readFileToString(new File(f));
}
public static void post(String text,String type) throws ClientProtocolException, IOException{
String res = HttpPostUtil.postString(ServerConfig.UPDATE_URL+"?commit=true", null, type, text);
info("Res: %s",res);
}
Deleting with Update handler
The url to delete data will be the same. The body content now is:
Searching API
Velocity Search UI
User can access built-in UI to demonstrates search features, the link is:
Where dblpsearch is core_name. You may need changing the port number and the core_name.
For other features please refer the book [reference guide 5.1, chap Searching].
SolrJ (Java API)
Solrj is a java client to access solr. It offers a java interface to add, update, and query the solr index.
Setting class path
There are several folders containing jars used by SolrJ: /dist, /dist/solrj-lib and /lib. A minimal set of jars (you may find need of others depending on your usage scenario) to use SolrJ is as follows:
From /dist:
- apache-solr-solrj-*.jar
From /dist/solrj-lib
- commons-codec-1.3.jar
- commons-httpclient-3.1.jar
- commons-io-1.4.jar
- jcl-over-slf4j-1.5.5.jar
- slf4j-api-1.5.5.jar
From /lib
- slf4j-jdk14-1.5.5.jar
For maven
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>prjsolr-demo</groupId>
<artifactId>Solr-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.solr</groupId>
<artifactId>solr-core</artifactId>
<version>5.1.0</version>
</dependency>
<dependency>
<artifactId>solr-solrj</artifactId>
<groupId>org.apache.solr</groupId>
<version>5.1.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.1.1</version>
</dependency>
</dependencies>
</project>
HttpSolrClient
From Solr 5.x, the client code can get accessed to server using HttpSolrClient. This class uses apache http client to connect to Solr Server.
public interface ServerConfig {
String SOLR_HOME = "D:/Framework/solr-5.1.0/solr-5.1.0/server/solr";
String SOLR_ROOT_URL = "http://127.0.0.1:8984/solr";
String SOLR_COLLECTION_URL = SOLR_ROOT_URL+"/postingrest";
public static final String COLLECTION_NAME = "postingrest";
String UPDATE_URL = SOLR_COLLECTION_URL+"/update";
}
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import connector.ServerConfig;
public class Connector {
public static SolrClient newConnection() {
return new HttpSolrClient(ServerConfig.SOLR_COLLECTION_URL);
}
public static void close(SolrClient client) {
try {
if (client != null)
client.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
EmbeddedSolrServer
The EmbeddedSolrServer provides the same interface without requiring an HTTP connection.
String SOLR_HOME = "D:/Framework/solr-5.1.0/solr-5.1.0/server/solr";
/**
* The collection must not be locked to be ran as EmbeddedServer. Hence, Instance of solr must be stopped.
* @throws Exception
*/
public static void byEmbeddedServer() throws Exception {
CoreContainer container = new CoreContainer(ServerConfig.SOLR_HOME);
container.load();
info("All core names: %s", container.getAllCoreNames());
EmbeddedSolrServer solr = new EmbeddedSolrServer(container,
ServerConfig.COLLECTION_NAME);
SolrQuery parameters = new SolrQuery();
parameters.set("q", "Lord");
QueryResponse response = solr.query(parameters);
info("RESULT %s", response);
SolrDocumentList results = response.getResults();
info("Results size: %s", results.size());
for (int i = 0; i < results.size(); ++i) {
info(results.get(i));
}
solr.close();
}
Adding data to Solr
SolrClient solr = Connector.newConnection();
// Add one document
SolrInputDocument sid = new SolrInputDocument();
//If ID isnot given by program, the system automatically generate new one. In this case, the next running with the same values, new record is inserted
sid.addField(Field.ID.me(), "hvn");
sid.addField(Field.NAME.me(), "HarveyNash - 0");
sid.addField(Field.TITLE.me(), "Organization");
sid.addField(Field.ADDR.me(), "HITC - Cau Giay");
solr.add(sid);
solr.commit();
sid = new SolrInputDocument();
sid.addField(Field.ID.me(), "gnx");
sid.addField(Field.NAME.me(), "The girl next table - 0");
sid.addField(Field.TITLE.me(), "Unknown");
sid.addField(Field.ADDR.me(), "HITC - Cau Giay");
solr.add(sid);
solr.commit();
Adding unstructured data to Solr
// indexing pdf manually
SolrClient solr = Connector.newConnection();
ContentStreamUpdateRequest req = new ContentStreamUpdateRequest(
"/update/extract");
//req.addFile(new File("./data/complex.pdf"),"application/pdf");
req.addFile(new File("./data/simple.pdf"),"application/pdf");
//req.setParam("literal.id","doc2");//to unique the document
req.setParam(ExtractingParams.EXTRACT_ONLY, "true");
NamedListresult = solr.request(req);
//solr.commit();//need commiting
//info("RESULT [[[%s]]]",result);
//testing with CSV
req = new ContentStreamUpdateRequest(
"/update/csv");
req.addFile(new File("./data/data.csv"),"text/csv");
//result = solr.request(req);//dont need to commit
info("Data: %s",result);
info("Successfully added!");
solr.close();
Deleting
Solr supports delete by ID, list of IDs, or by query:
SolrClient solr = Connector.newConnection();
solr.deleteById(list_of_strings);
Or if we want to delete all the indexed records:
SolrClient solr = Connector.newConnection();
solr.deleteByQuery("*:*");//*:* means to all records
solr.close();
Searching
Solr supports different query parser which helps us easily querying with different feature.
Example: method below accepts a query array with two elements, the first element is name of parameter of each type of parser, and the second is value. For instance, the query name is “q” (Standard query parser) and the value is “Batman Nightwish”.
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocumentList;
import connector.T;
public class Searching extends T{
public static void main(String[] args) throws Exception{
byStandardQueryParser(new String[]{"q","Batman Nightwish"}, new String[]{"fq","address_s:'not given'"});//"q","address_s:'not given'"
}
public static void byStandardQueryParser(String[]... query) throws Exception{
SolrClient solr = Connector.newConnection();
SolrQuery params = new SolrQuery();
for(String[] arr: query){
params.set(arr[0], arr[1]);
}
QueryResponse response = solr.query(params);
SolrDocumentList results = response.getResults();
info("Results: %s",results);
solr.close();
}
}
Data Import Handler
Data Import Handler is a tool which helps us import data from RDBMS, RSS, or Email. To enable DIH in Solr, we have to add following line to solr-config.xml:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
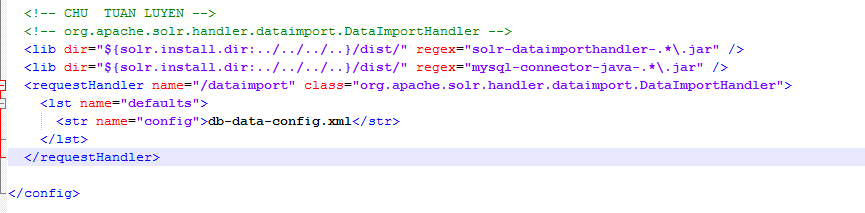
Where db-data-config.xml is file I config database information. Note that the database java driver have to put to folder /dist/ and adding a line to solr-config.xml.
pk="id"
deltaQuery="select t.id as id from t where inserted > '${dataimporter.last_index_time}'">
|
pk="id"
deltaQuery="select t.id as id from article where inserted > '${dataimporter.last_index_time}'">
In this case, I declared two entity and picked few columns in the table to be imported. After that, we can reload the core by admin interface.

The data import field:

We can choose full-import or delta Import (import from the last time only). Just execute and relax....
The velocity browser after I imported several records:
Customizing
Ranking
Data import handler
Personalization
Evaluation
Bring Solr To UI Application: DBLP Search
Overview
- This application is used to evaluate the performance of Solr.
- DBLP stands for: Digital Bibliography & Library Project
- Dataset:
- Type: one xml file ~ 1.5GB
- Article tags number=1287564
- InProceedings tags number=1622967
- Proceedings tags number=26861
- Incollection tags number=32325
- Requirement:
- Provide fast searching in more than 1.2 million records.
Solution
Based on requirements, I created one simple web application, and many jobs (scheduled tasks) to read data/index data. I also linked to a RDBMS (MySQL in this case). The people can evaluate the performance of searching in >1 million records from MySQL. The system architecture is drawn below:
The users use browsers to connect to dblp search, which is a web container has been written in Play! Framework. This application use SolrJ API to connect to Solr Instance. Whilst the dataset is stored as one xml file, and approximately 1.5GB.
- ImporterJobs will pre-parse this xml file, it creates many smaller xml file. Other threads parse these smaller files, and push the value into synchronized queue. Several threads are used to get content from these queues, and insert into RDBMS using JPA (or any ORM tool).
- Another jobs’ name is IndexerJobs: multiple threads are used to read data from RDBMS using JPA, push them into queues, multiple threads are used to process queue: indexing, finally, multiple threads are used to save state of indexed items.
Sequence Diagram
Class Diagram
- Parser
- ImporterJobs in standalone application:

- ImporterJobs in Play! Application:
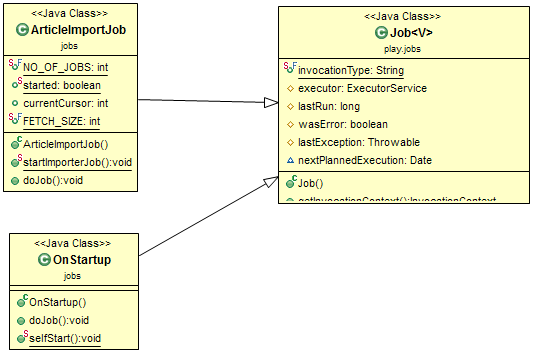
- IndexerJobs in Play! Application:

Implementation
Some important notes would be noted:
- Current paging is not using cursor which is many times faster in abundant data.
UI


Conclusion
References
Sources
No comments:
Post a Comment